Conversational Memory
Discover how conversational memory enhances chatbot interactions by allowing AI to recall past conversations. Learn about different memory types in LangChain, including ConversationBufferMemory and ConversationSummaryMemory, and see token usage comparisons through detailed graphs. Improve your AI’s coherence and relevance in conversations!
What is Conversational Memory?
Conversational memory is the ability of a chatbot to respond to multiple queries in a seamless, chat-like manner. It ensures coherence in conversations by allowing the chatbot to remember previous interactions, unlike a stateless model that treats every query as independent.
Comparing LLMs With and Without Conversational Memory
In a conversation, blue boxes represent user prompts, and gray boxes show the LLM’s responses. Without conversational memory, the LLM cannot recall past interactions and responds to each query independently.
Implementing Conversational Memory
By default, LLMs are stateless, meaning each query is processed without considering previous interactions. However, conversational memory allows the LLM to remember past conversations, which is crucial for applications like chatbots.
Conversational memory can be implemented in various ways. In the context of LangChain, all methods build upon the ConversationChain.
Setting Up ConversationChain
Start by initializing the ConversationChain. We will use OpenAI’s text-davinci-003 as the LLM, but other models like gpt-3.5-turbo can also be used.
from langchain import OpenAI
from langchain.chains import ConversationChain
# Initialize the large language model
llm = OpenAI(
temperature=0,
openai_api_key="OPENAI_API_KEY",
model_name="text-davinci-003"
)
# Initialize the conversation chain
conversation = ConversationChain(llm=llm)You can view the prompt template used by the ConversationChain:
print(conversation.prompt.template)The template primes the model for a friendly conversation between a human and an AI, with a focus on specific details from its context.
Types of Conversational Memory
ConversationBufferMemory
The simplest form of conversational memory. It stores the entire conversation history in its raw form, which is then passed to the history parameter.
from langchain.chains.conversation.memory import ConversationBufferMemory
conversation_buf = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)Example interaction with token counts:
from langchain.callbacks import get_openai_callback
def count_tokens(chain, query):
with get_openai_callback() as cb:
result = chain.run(query)
print(f'Spent a total of {cb.total_tokens} tokens')
return result
count_tokens(conversation_buf, "Good morning AI!")
count_tokens(conversation_buf, "My interest here is to explore the potential of integrating Large Language Models with external knowledge")
count_tokens(conversation_buf, "I just want to analyze the different possibilities. What can you think of?")
count_tokens(conversation_buf, "Which data source types could be used to give context to the model?")
count_tokens(conversation_buf, "What is my aim again?")print(conversation_buf.memory.buffer)###output####
Good morning! It's a beautiful day today, isn't it? How can I help you?
Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Is there anything else I can help you with?
Well, integrating Large Language Models with external knowledge can open up a lot of possibilities. For example, you could use them to generate more accurate and detailed summaries of text, or to answer questions about a given context more accurately. You could also use them to generate more accurate translations, or to generate more accurate predictions about future events.
There are a variety of data sources that could be used to give context to a Large Language Model. These include structured data sources such as databases, unstructured data sources such as text documents, and even audio and video data sources. Additionally, you could use external knowledge sources such as Wikipedia or other online encyclopedias to provide additional context.
Your aim is to explore the potential of integrating Large Language Models with external knowledge.
Human: Good morning AI!
AI: Good morning! It's a beautiful day today, isn't it? How can I help you?
Human: My interest here is to explore the potential of integrating Large Language Models with external knowledge
AI: Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Is there anything else I can help you with?
Human: I just want to analyze the different possibilities. What can you think of?
AI: Well, integrating Large Language Models with external knowledge can open up a lot of possibilities. For example, you could use them to generate more accurate and detailed summaries of text, or to answer questions about a given context more accurately. You could also use them to generate more accurate translations, or to generate more accurate predictions about future events.
Human: Which data source types could be used to give context to the model?
AI: There are a variety of data sources that could be used to give context to a Large Language Model. These include structured data sources such as databases, unstructured data sources such as text documents, and even audio and video data sources. Additionally, you could use external knowledge sources such as Wikipedia or other online encyclopedias to provide additional context.
Human: What is my aim again?
AI: Your aim is to explore the potential of integrating Large Language Models with external knowledge.Pros and Cons:
- Pros: Maximum information retention, simple implementation.
- Cons: Increased tokens lead to slower responses and higher costs, limited by token limit for long conversations.
ConversationSummaryMemory
Summarizes the conversation history to avoid excessive token usage. It requires an LLM to generate the summaries.
from langchain.chains.conversation.memory import ConversationSummaryMemory
conversation_sum = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
print(conversation_sum.memory.prompt.template)
count_tokens(conversation_sum, "Good morning AI!")
count_tokens(conversation_sum, "My interest here is to explore the potential of integrating Large Language Models with external knowledge")
count_tokens(conversation_sum, "I just want to analyze the different possibilities. What can you think of?")
count_tokens(conversation_sum, "Which data source types could be used to give context to the model?")
count_tokens(conversation_sum, "What is my aim again?")
# View the conversation summary
print(conversation_sum.memory.buffer)##output##
Good morning! It's a beautiful day today, isn't it? How can I help you?
That sounds like an interesting project! I'm familiar with Large Language Models, but I'm not sure how they could be integrated with external knowledge. Could you tell me more about what you have in mind?
I can think of a few possibilities. One option is to use a large language model to generate a set of candidate answers to a given query, and then use external knowledge to filter out the most relevant answers. Another option is to use the large language model to generate a set of candidate answers, and then use external knowledge to score and rank the answers. Finally, you could use the large language model to generate a set of candidate answers, and then use external knowledge to refine the answers.
There are many different types of data sources that could be used to give context to the model. These could include structured data sources such as databases, unstructured data sources such as text documents, or even external APIs that provide access to external knowledge. Additionally, the model could be trained on a combination of these data sources to provide a more comprehensive understanding of the context.
Your aim is to explore the potential of integrating Large Language Models with external knowledge.
The human greeted the AI with a good morning, to which the AI responded with a good morning and asked how it could help. The human expressed interest in exploring the potential of integrating Large Language Models with external knowledge, to which the AI responded positively and asked for more information. The human asked the AI to think of different possibilities, and the AI suggested three options: using the large language model to generate a set of candidate answers and then using external knowledge to filter out the most relevant answers, score and rank the answers, or refine the answers. The human then asked which data source types could be used to give context to the model, to which the AI responded that there are many different types of data sources that could be used, such as structured data sources, unstructured data sources, or external APIs. Additionally, the model could be trained on a combination of these data sources to provide a more comprehensive understanding of the context. The human then asked what their aim was again, to which the AI responded that their aim was to explore the potential of integrating Large Language Models with external knowledge.Pros and Cons:
- Pros: Reduced token usage for long conversations, enables longer interactions.
- Cons: Higher token usage for short conversations, reliance on summarization accuracy
- Graph: Token Count for Buffer Memory vs. Summary Memory
ConversationBufferWindowMemory
This method retains only a specified number of recent interactions, effectively limiting the number of tokens used.
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# Initialize the conversation chain with buffer window memory
conversation_bufw = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
# Example interactions
print(conversation_bufw("Good morning AI!"))
print(conversation_bufw("My interest here is to explore the potential of integrating Large Language Models with external knowledge"))
print(conversation_bufw("I just want to analyze the different possibilities. What can you think of?"))
print(conversation_bufw("Which data source types could be used to give context to the model?"))
print(conversation_bufw("What is my aim again?"))
# View the conversation history in the window
bufw_history = conversation_bufw.memory.load_memory_variables(inputs=[])['history']
print(bufw_history)The effective “memory” of the model:
##output##
Good morning! It's a beautiful day today, isn't it? How can I help you?
Interesting! Large Language Models are a type of artificial intelligence that can process natural language and generate text. They can be used to generate text from a given context, or to answer questions about a given context. Integrating them with external knowledge can help them to better understand the context and generate more accurate results. Do you have any specific questions about this integration?
There are many possibilities for integrating Large Language Models with external knowledge. For example, you could use external knowledge to provide additional context to the model, or to provide additional training data. You could also use external knowledge to help the model better understand the context of a given text, or to help it generate more accurate results.
Data sources that could be used to give context to the model include text corpora, structured databases, and ontologies. Text corpora provide a large amount of text data that can be used to train the model and provide additional context. Structured databases provide structured data that can be used to provide additional context to the model. Ontologies provide a structured representation of knowledge that can be used to provide additional context to the model.
Your aim is to use data sources to give context to the model.
Human: What is my aim again?
AI: Your aim is to use data sources to give context to the model.Pros and Cons:
- Pros: Limits token usage, adjustable window size.
- Cons: Cannot remember distant interactions.
- Graph: Token Count for Buffer Window Memory
ConversationSummaryBufferMemory
Combines summarization and buffer memory to maintain a balance between recent and distant interactions.
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
conversation_sum_bufw = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(llm=llm, max_token_limit=650)
)
###Example conversation with a token limit:
count_tokens(conversation_sum_bufw, "Good morning AI!")
count_tokens(conversation_sum_bufw, "My interest here is to explore the potential of integrating Large Language Models with external knowledge")
count_tokens(conversation_sum_bufw, "I just want to analyze the different possibilities. What can you think of?")
count_tokens(conversation_sum_bufw, "Which data source types could be used to give context to the model?")
count_tokens(conversation_sum_bufw, "What is my aim again?")###ouput###
Message: Good morning AI!
Response: [AI response]
Current token count: 3
Message: My interest here is to explore the potential of integrating Large Language Models with external knowledge
Response: [AI response]
Current token count: 23
Message: I just want to analyze the different possibilities. What can you think of?
Response: [AI response]
Current token count: 40
Message: Which data source types could be used to give context to the model?
Response: [AI response]
Current token count: 56
Message: What is my aim again?
Response: [AI response]
Current token count: 69
Pros and Cons:
- Pros: Retains distant interactions through summarization, maintains recent interactions in raw form.
- Cons: Requires careful tuning of what to summarize and what to buffer.
Comparison Graph:
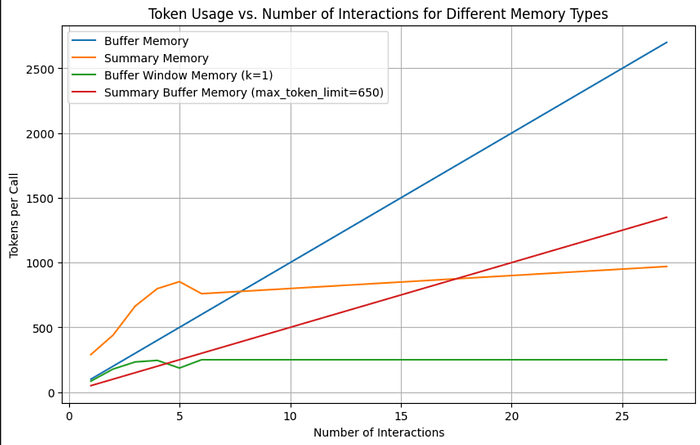
Conclusion
Conversational memory enhances the ability of LLMs to maintain coherent and contextually aware conversations. Whether through buffer memory, summarization, windowed memory, or a combination, each method offers unique advantages and trade-offs, allowing developers to choose the best approach for their specific use case. For more detailed information, visit the LangChain Conversational Memory page.
